Introduction to quantification#
Quantification (a.k.a. class-prevalence estimation) asks a different question from classification. A classifier predicts the label of each individual instance; a quantifier predicts the proportion of each class in a whole sample — and it can be accurate even when the underlying classifier is not.
This first example fits the simplest possible quantifier,
CC (Classify & Count), predicts the class
prevalence of a test sample, and compares the estimate against the ground
truth.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from mlquantify.counting import CC
from mlquantify.metrics import MAE
# A binary problem whose test split is intentionally more imbalanced
# than training, so counting alone has to work for its estimate.
X, y = make_classification(
n_samples=4000, n_features=20, weights=[0.5, 0.5], random_state=0,
)
X_tr, X_te, y_tr, y_te = train_test_split(
X, y, test_size=0.5, stratify=y, random_state=0,
)
quantifier = CC(LogisticRegression(max_iter=1000))
quantifier.fit(X_tr, y_tr)
pred = quantifier.predict(X_te) # dict {class: prevalence}
pred = np.array([pred[c] for c in quantifier.classes_])
true = np.array([(y_te == c).mean() for c in quantifier.classes_])
# Side-by-side bars: true vs. predicted prevalence per class.
fig, ax = plt.subplots(figsize=(6, 4))
x = np.arange(len(quantifier.classes_))
ax.bar(x - 0.2, true, width=0.4, label="true", color="#264653")
ax.bar(x + 0.2, pred, width=0.4, label="predicted (CC)", color="#2a9d8f")
ax.set_xticks(x)
ax.set_xticklabels([f"class {c}" for c in quantifier.classes_])
ax.set_ylabel("Prevalence")
ax.set_ylim(0, 1)
ax.set_title(f"CC prevalence estimate (mean absolute error = {MAE(true, pred):.3f})")
ax.legend()
fig.tight_layout()
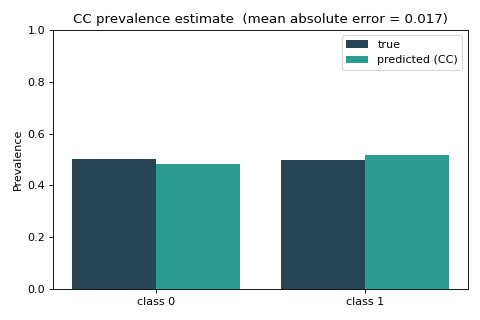
The two bars almost coincide: when the test distribution resembles training, even plain counting does well. The next example shows what happens when it does not — and why dedicated quantifiers exist.
See also
Why counting fails under prior shift — the limits of plain counting.
Getting Started — the same workflow in narrative form.