2.6. Likelihood-Based Quantification#
Likelihood-based methods estimate class prevalences by maximising the likelihood of the observed posterior probabilities under the assumption of prior probability shift — the feature distributions within each class do not change, only the class proportions do.
They are among the most accurate single-model quantifiers and should be your first upgrade from the counting family.
2.6.1. Prior Probability Shift — The Core Assumption#
All methods on this page assume:
Under this assumption, the classifier’s posterior probability for a test instance \(x\) is distorted by the wrong priors baked in at training time. Bayes’ theorem tells us how to correct it:
where \(Z\) is a normalisation constant. Likelihood-based methods iterate this correction together with updating \(P_U(y)\) until convergence.
2.6.2. MLPE — Maximum Likelihood Prevalence Estimation (trivial baseline)#
MLPE is the trivial likelihood baseline: it simply returns the
training-set prevalence as the estimate for any test set, assuming no shift.
Why it exists: MLPE provides the lower bound of what a method should achieve. If your quantifier cannot beat MLPE, something is wrong. It is also the starting point of EMQ (see below).
from mlquantify.likelihood import MLPE
from sklearn.linear_model import LogisticRegression
q = MLPE(LogisticRegression())
q.fit(X_train, y_train)
print(q.predict(X_test))
# Returns training prevalence regardless of X_test
2.6.3. EMQ — Expectation-Maximization Quantifier (SLD)#
EMQ (also known as SLD for Saerens–Latinne–Decaestecker) is the
most important single quantifier in mlquantify. It iteratively adjusts
posterior probabilities to find the class prevalences that maximise the
likelihood of the observed test data.
The algorithm has two alternating steps:
E-step — correct each posterior using the current prevalence estimate:
M-step — update the prevalence estimate as the mean of corrected posteriors:
Starting from \(\hat{p}^{(0)} = p_L\) (MLPE), EMQ converges to the maximum-likelihood prevalence estimate. (Saerens et al., 2002; Alexandari et al., 2020)
Why it excels: EMQ corrects for the exact form of distortion caused by prior probability shift. Esuli et al. (2023) show it is consistently among the top performers across benchmarks when the shift assumption holds.
2.6.3.1. Parameters#
Parameter |
Default |
Explanation |
|---|---|---|
|
|
A probabilistic classifier with |
|
|
Convergence threshold. The algorithm stops when the MAE between
successive prevalence estimates falls below this value. The default
balances speed and accuracy. Reduce to |
|
|
Maximum EM iterations. Almost always converges in < 20 iterations. Raise to 500 if you see convergence warnings. |
|
|
Optional calibration applied to posteriors before the EM loop. Calibration corrects overconfident or underconfident probability outputs, which can significantly improve EMQ accuracy. Options:
|
|
|
What to do if calibration fails (e.g. due to numerical issues).
|
|
|
Convergence criterion comparing successive prevalence estimates. The default MAE is appropriate for all problem types. |
2.6.3.2. Examples#
Basic usage with Logistic Regression (recommended):
from mlquantify.likelihood import EMQ
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
X, y = make_classification(n_samples=1000, weights=[0.8, 0.2],
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42)
q = EMQ(LogisticRegression())
q.fit(X_train, y_train)
print(q.predict(X_test))
# {0: 0.80, 1: 0.20}
With BCTS calibration (best for neural/overconfident classifiers):
from mlquantify.likelihood import EMQ
from sklearn.neural_network import MLPClassifier
q = EMQ(MLPClassifier(hidden_layer_sizes=(100,), max_iter=500),
calib_function='bcts')
q.fit(X_train, y_train)
print(q.predict(X_test))
Using aggregate directly with pre-computed posteriors:
import numpy as np
from mlquantify.likelihood import EMQ
from sklearn.linear_model import LogisticRegression
# Fit just the classifier
clf = LogisticRegression().fit(X_train, y_train)
proba_train = clf.predict_proba(X_train)
proba_test = clf.predict_proba(X_test)
q = EMQ(clf)
q.fit(X_train, y_train)
# aggregate(test_posteriors, train_posteriors, train_labels)
print(q.aggregate(proba_test, proba_train, y_train))
Multiclass (EMQ is natively multiclass):
from mlquantify.likelihood import EMQ
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=800, n_classes=4,
n_informative=6, n_redundant=0,
random_state=42)
X_train, X_test = X[:600], X[600:]
y_train, y_test = y[:600], y[600:]
q = EMQ(LogisticRegression())
q.fit(X_train, y_train)
print(q.predict(X_test))
# {0: 0.25, 1: 0.25, 2: 0.25, 3: 0.25}
Tip
EMQ with calib_function='bcts' is the single best-performing method
in Alexandari et al. (2020)’s large benchmark of label-shift methods. Use
it as the primary quantifier when prior probability shift is expected.
When EMQ struggles
EMQ assumes prior probability shift. If the features of a class change
between training and test (concept drift), or if the class-conditional
distributions overlap heavily and the classifier is poorly calibrated,
EMQ’s correction can overshoot. In these cases, distribution-matching
methods like DyS or
KDEyHD may be more robust.
2.6.4. CDE — CDE-Iterate (threshold-adjustment via cost ratios)#
CDE estimates binary class prevalence by iteratively adjusting the
decision threshold using the ratio of misclassification costs derived from
the training priors and the current prevalence estimate.
At each step, the threshold \(\tau\) is set such that a false negative and a false positive have equal expected cost:
where \(c_{FP}\) is updated from the current prevalence estimate. The process repeats until the estimated positive proportion stabilises.
Why it exists: CDE was proposed by Barranquero et al. (2015) as an iterative threshold-selection method that avoids cross-validation entirely. It is lighter than EMQ (no full posterior re-weighting) and often competitive with threshold-adjustment methods on binary problems.
Binary-only — multiclass via OvR.
2.6.4.1. Parameters#
Parameter |
Default |
Explanation |
|---|---|---|
|
|
Probabilistic classifier. |
|
|
Convergence tolerance on the positive prevalence between iterations. |
|
|
Maximum iterations. Typically converges in < 20 steps. |
|
|
Initial false-positive cost. The algorithm starts with equal misclassification costs (\(c_{FP} = c_{FN} = 1\)). Change if you have domain knowledge about the true cost ratio. |
|
|
Multiclass decomposition. |
|
|
Parallel jobs. |
2.6.4.2. Examples#
from mlquantify.likelihood import CDE
from sklearn.linear_model import LogisticRegression
q = CDE(LogisticRegression(), tol=1e-5)
q.fit(X_train, y_train)
print(q.predict(X_test))
# {0: 0.80, 1: 0.20}
Using aggregate with pre-computed posteriors:
clf = LogisticRegression().fit(X_train, y_train)
proba_test = clf.predict_proba(X_test)
q = CDE(clf)
q.fit(X_train, y_train)
print(q.aggregate(proba_test, train_labels=y_train))
2.6.5. Method Comparison#
Method |
Multiclass |
Needs proba |
Extra fit cost |
Best for |
|---|---|---|---|---|
MLPE |
✓ |
✓ |
None |
Baseline; no shift expected. |
EMQ |
✓ |
✓ |
None |
Prior probability shift; recommended default. |
EMQ+BCTS |
✓ |
✓ |
Calibration |
Overconfident classifiers (neural nets, forests). |
CDE |
✗ (OvR) |
✓ |
None |
Binary problems; lightweight alternative to EMQ. |
Practical recommendation:
Use EMQ as your primary quantifier in most scenarios.
Add
calib_function='bcts'when your classifier tends to be overconfident.Use CDE when you want a fast, calibration-free alternative for binary tasks.
Always compare against MLPE to verify your method is actually learning something.
See also
Distribution Matching for methods that do not rely on the prior-shift assumption and can handle more general distributional changes.
Likelihood-based methods (Maximum Likelihood) aim to estimate class prevalences in the test set \(U\), assuming that the class distribution (priors) has changed, but the probability densities within each class (\(P(X|Y)\)) have remained the same (Prior Probability Shift).
2.6.6. Maximum Likelihood Prevalence Estimation (MLPE)#
The Maximum Likelihood Prevalence Estimation (MLPE), defined in MLPE, is the simplest strategy and is considered a trivial starting point or baseline. It naively assumes that the class distribution in the test set (\(U\)) is the same as in the training set (\(L\)).
MLPE is not a “true” quantification method but rather a trivial strategy. It simply takes the observed prevalence in the training set and uses it as the estimate for the test set. If there were no dataset shift (change in distribution), MLPE would be the optimal quantification strategy.
2.6.7. Expectation Maximization for Quantification (EMQ)#
The Expectation Maximization for Quantification (EMQ), defined in EMQ (also known as SLD — Saerens, Latinne, Decaestecker) [1], is an transductive algorithm that uses a transductive correction of posterior probabilities to estimate class prevalences in the test set \(U\) by maximizing the likelihood of the observed data [2].
The SLD algorithm is based on the Expectation-Maximization (EM) framework, which is an iterative method for finding maximum likelihood estimates in models with latent variables. The EMQ works by:
Adjusting classifier outputs: It adjusts the outputs of a probabilistic classifier to correspond to new prior probabilities (prevalences) without the need to retrain the classification model. As a byproduct of this process, it also estimates the new prior probabilities.
Iterative refinement: EMQ is a mutually recursive process that iterates by incrementally updating posterior probabilities (E-Step) and then class prevalences (M-Step) until the process converges.
Convergence guarantee: The algorithm converges to a global maximum of the likelihood estimate, as the likelihood function is concave and bounded.
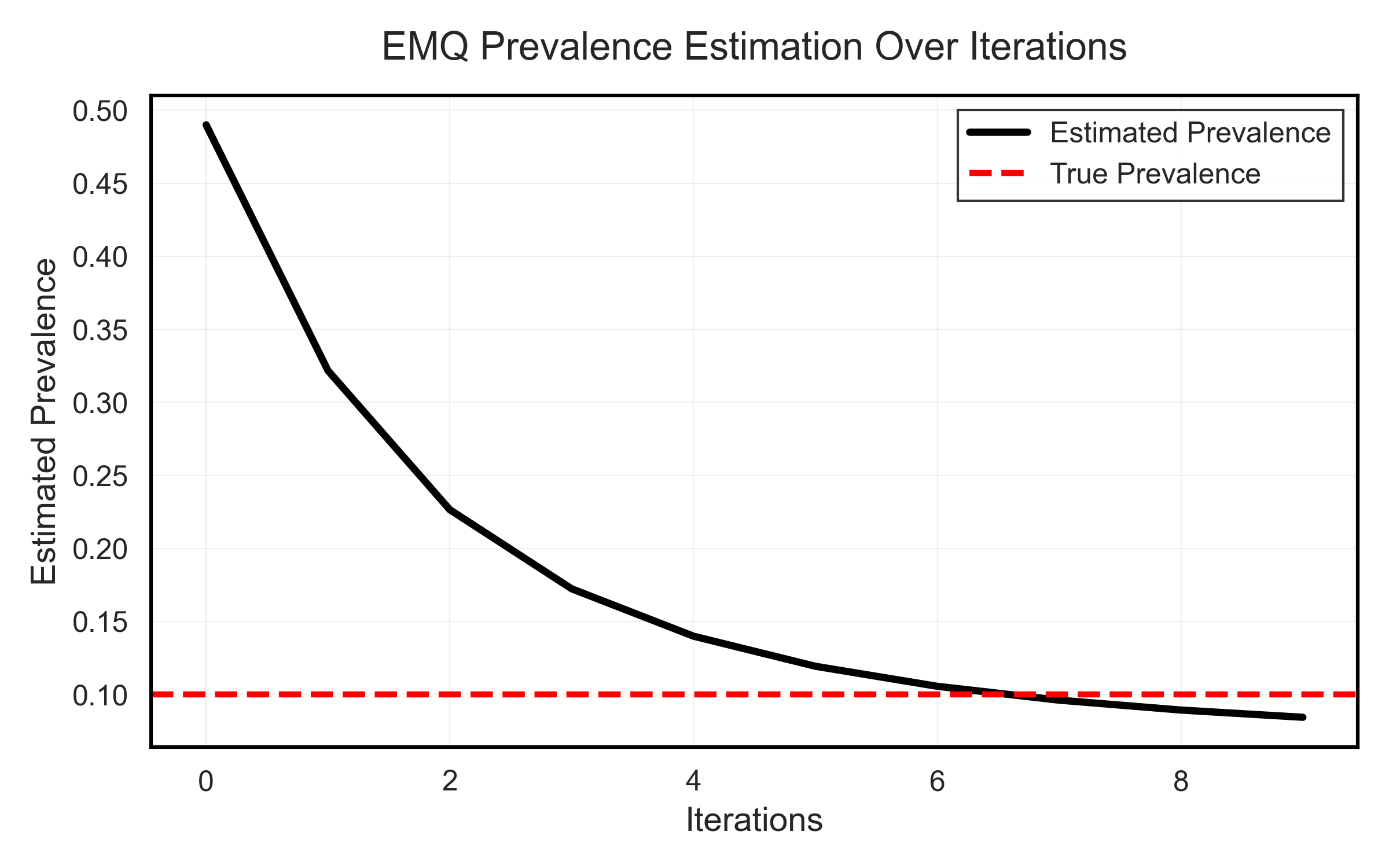
Expectation Maximization Illustration for a binary scenario (looking only at the positive class)#
The method starts at Iteration 0, where the initial estimated prevalence \(\hat{p}^{(0)}_U(y)\) is defined as the training set prevalence \(p_L(y)\) (i.e., the MLPE estimate, or priors). From there, EMQ uses iteration to adjust this initial estimate.
Mathematical details - EMQ Algorithm
EMQ iterates between the E and M steps, based on:
\(\hat{p}^{(s)}_U(\omega_i)\): Estimated prevalence of class \(\omega_i\) at iteration \(s\).
\(\hat{p}_L(\omega_i)\): Prior probability of class \(\omega_i\) in the source domain (training).
\(\hat{p}_L(\omega_i \mid x_k)\): Posterior probability of \(x_k\) belonging to class \(\omega_i\), provided by the calibrated classifier.
Initialization (Iteration s=0)
For each class \(y \in Y\):
E-Step (Expectation) - Posterior Probability Correction
Calculates the corrected posterior probability, \(p^{(s)}(\omega_i \mid x_k)\). This step adjusts the classifier output probabilities using the ratio between the new estimated prevalence and the training prevalence:
M-Step (Maximization) - Prevalence Update
The new prevalence estimate (\(\hat{p}^{(s)}_U(\omega_i)\)) is the average of the corrected posterior probabilities over all \(N\) samples in the test set \(U\):
The EMQ iterates the E and M steps until the prevalence parameters converge [1] [2].
Example
from mlquantify.likelihood import EMQ
from sklearn.linear_model import LogisticRegression
# EMQ requires a probabilistic classifier (soft classifier)
q = EMQ(estimator=LogisticRegression())
q.fit(X_train, y_train)
# Updates predictions based on the test distribution iteratively
q.predict(X_test)
# -> adjusted prevalence dictionary