13.1.1. Representations#
Representations turn a sample of instances (or classifier scores) into the fixed-length descriptor that a distribution-matching quantifier compares. They are what specialises a single matching skeleton into different methods: swapping the representation is exactly what turns the same mixture-matching idea into HDy, EDy, MMD or KDEy.
13.1.1.1. Role and mechanism#
A representation \(r(\cdot)\) maps a set of instances to a vector, so that a
candidate prevalence \(p\) produces a mixed representation
\(\sum_c p_c\, r_c\) from the per-class descriptors \(r_c\). The
quantifier then searches for the \(p\) whose mixture best matches the test
descriptor \(r_U\) under a chosen loss. Fitting a representation computes the
per-class descriptors (class_representations_); transform produces the
descriptor of a new sample. BaseRepresentation defines the common
fit / transform interface; custom representations subclass it.
The sections below describe each representation type and the descriptor it produces; the summary table at the end compares them and explains how to choose.
13.1.1.2. Histogram representation#
HistogramRepresentation bins the classifier scores (or features) and
stores one normalised histogram per class. It is the most widely used
representation, and its two most important parameters — bins and
bin_edges — are easiest to understand by seeing the descriptor they produce.
``bins`` — resolution. bins sets how many intervals the score range is
split into. Few bins give a coarse, stable summary; many bins capture fine
structure but need more data to fill each bin reliably.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import HistogramRepresentation
rng = np.random.default_rng(0)
scores = rng.beta(2, 5, size=(2000, 1)) # classifier scores in [0, 1]
y = (scores[:, 0] > 0.3).astype(int)
fig, axes = plt.subplots(1, 3, figsize=(9, 2.8), sharey=True)
for ax, n in zip(axes, (5, 10, 25)):
rep = HistogramRepresentation(bins=(n,), range=(0.0, 1.0)).fit(scores, y)
h = rep.transform(scores) # normalised mass per bin
edges = np.linspace(0, 1, n + 1)
ax.bar((edges[:-1] + edges[1:]) / 2, h, width=(1.0 / n) * 0.9,
color="#2a7ab9", edgecolor="white", linewidth=0.5)
ax.set_title(f"bins = {n}", fontsize=10)
ax.set_xlabel("classifier score")
ax.set_xlim(0, 1)
axes[0].set_ylabel("normalised mass")
fig.tight_layout()
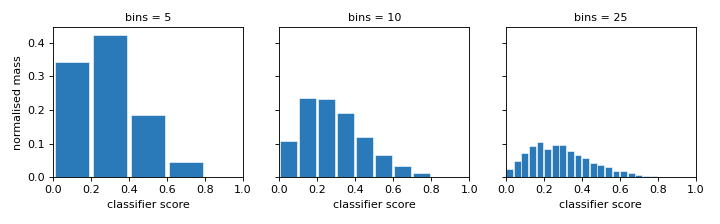
More bins means a finer (but noisier) summary of the same scores.#
``bin_edges`` — where the bins are placed. With 'fixed' (the default) the
bins are equal-width over the range parameter ([0, 1] by default), so
bins outside the region where the data actually falls stay empty and are wasted.
With 'auto' the edges are learned at fit time from the data range, so all
bins are packed where the scores actually are — giving more usable resolution on
skewed or concentrated score distributions. The grey band marks the true data
range.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import HistogramRepresentation
rng = np.random.default_rng(3)
scores = 0.2 + 0.3 * rng.beta(2, 3, size=(3000, 1)) # concentrated in [0.2, 0.5]
y = (scores[:, 0] > scores[:, 0].mean()).astype(int)
n = 12
fig, axes = plt.subplots(1, 2, figsize=(8, 3), sharey=True)
rep_fixed = HistogramRepresentation(bins=(n,), range=(0.0, 1.0),
bin_edges="fixed").fit(scores, y)
hf = rep_fixed.transform(scores)
ef = np.linspace(0, 1, n + 1)
axes[0].bar((ef[:-1] + ef[1:]) / 2, hf, width=np.diff(ef) * 0.9,
color="#b9542a", edgecolor="white", linewidth=0.5)
axes[0].set_title("bin_edges='fixed'\n(equal width over range=[0, 1])", fontsize=10)
rep_auto = HistogramRepresentation(bins=(n,), bin_edges="auto").fit(scores, y)
ha = rep_auto.transform(scores)
ea = rep_auto.edges_[0][0] # learned edges
axes[1].bar((ea[:-1] + ea[1:]) / 2, ha, width=np.diff(ea) * 0.9,
color="#2a9b5c", edgecolor="white", linewidth=0.5)
axes[1].set_title("bin_edges='auto'\n(edges fit to the data range)", fontsize=10)
for ax in axes:
ax.set_xlim(0, 1)
ax.set_xlabel("classifier score")
ax.axvspan(scores.min(), scores.max(), color="0.85", zorder=0)
axes[0].set_ylabel("normalised mass")
fig.tight_layout()
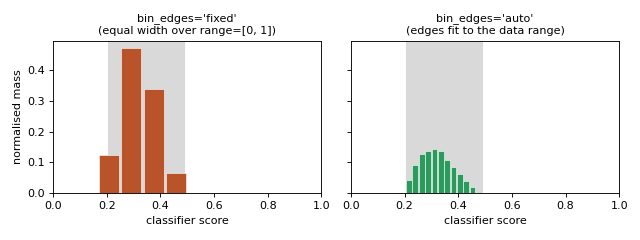
bin_edges='fixed' wastes bins outside the data; 'auto' adapts.#
Class-conditional distributions — what gets stored. A fitted
HistogramRepresentation keeps one normalised histogram per class
(class_representations_). The descriptor is discriminative only when those
per-class distributions differ: when the classifier separates the classes the
histograms barely overlap (easy to quantify), and when it does not they look
alike (hard), regardless of how the bins are configured.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import HistogramRepresentation
n = 12
edges = np.linspace(0, 1, n + 1)
centers = (edges[:-1] + edges[1:]) / 2
rng = np.random.default_rng(7)
fig, axes = plt.subplots(1, 2, figsize=(8.5, 3), sharey=True)
scenarios = [("well-separated classes", (2, 6), (6, 2)),
("overlapping classes", (3, 3), (4, 3))]
for ax, (title, (an, bn), (ap, bp)) in zip(axes, scenarios):
neg = rng.beta(an, bn, size=900)
pos = rng.beta(ap, bp, size=600)
scores = np.concatenate([neg, pos]).reshape(-1, 1)
y = np.concatenate([np.zeros(900), np.ones(600)]).astype(int)
rep = HistogramRepresentation(bins=(n,), range=(0, 1)).fit(scores, y)
ax.bar(centers, rep.class_representations_[0], width=1 / n * 0.9,
alpha=0.6, color="#4477aa", label="negative class")
ax.bar(centers, rep.class_representations_[1], width=1 / n * 0.9,
alpha=0.6, color="#cc6677", label="positive class")
ax.set_title(title, fontsize=10)
ax.set_xlabel("classifier score")
axes[0].set_ylabel("normalised mass")
axes[0].legend(fontsize=8)
fig.tight_layout()
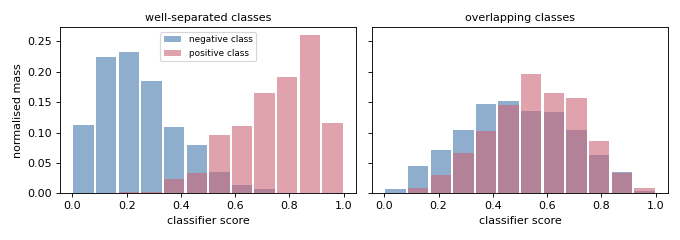
One histogram per class is stored; matching is easy only when they differ.#
The remaining parameters are minor: for a single score mode='onehot' yields
essentially the same per-bin vector as the default 'histogram';
laplace_smoothing=True adds a small floor that removes empty bins (stabilising
ratio- and log-based distances such as Hellinger); and features selects which
columns are histogrammed.
13.1.1.3. Density (KDE) representation#
KDERepresentation replaces the bins with a smooth per-class kernel
density over the posteriors. bandwidth is its key control: too small and each
class density spikes on its training points (over-fitting); too large and the
class densities blur together, erasing the separation the quantifier relies on.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import KDERepresentation
rng = np.random.default_rng(11)
X = np.concatenate([rng.normal(0.3, 0.12, 400),
rng.normal(0.65, 0.12, 300)]).reshape(-1, 1)
y = np.concatenate([np.zeros(400), np.ones(300)]).astype(int)
grid = np.linspace(-0.1, 1.1, 200).reshape(-1, 1)
fig, axes = plt.subplots(1, 3, figsize=(9.5, 2.8), sharey=True)
for ax, bw, tag in zip(axes, (0.02, 0.1, 0.4), ("too small", "good", "too large")):
rep = KDERepresentation(bandwidth=bw).fit(X, y)
ax.plot(grid[:, 0], np.exp(rep.class_representations_[0].score_samples(grid)),
color="#4477aa", label="negative")
ax.plot(grid[:, 0], np.exp(rep.class_representations_[1].score_samples(grid)),
color="#cc6677", label="positive")
ax.set_title(f"bandwidth = {bw} ({tag})", fontsize=9)
ax.set_xlabel("feature")
axes[0].set_ylabel("density")
axes[0].legend(fontsize=8)
fig.tight_layout()
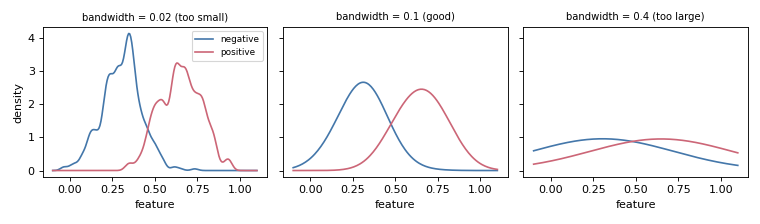
bandwidth trades off over-fitting (left) against over-smoothing (right).#
Unlike histograms, the KDE is smooth and multivariate, so it scales to several classes on the posterior simplex where bin-based representations fragment.
13.1.1.4. Distance representation#
DistanceRepresentation summarises a sample by its mean distance to
each class, producing one (n_classes,) descriptor. It carries no per-bin
shape, but it discriminates because a sample sits closer (on average) to its own
class — these distances are the terms of the energy-distance objective.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import DistanceRepresentation
rng = np.random.default_rng(0)
X0 = rng.normal(-1.3, 0.8, (300, 6))
X1 = rng.normal(1.3, 0.8, (300, 6))
X = np.vstack([X0, X1])
y = np.r_[np.zeros(300), np.ones(300)].astype(int)
rep = DistanceRepresentation().fit(X, y)
d0 = np.asarray(rep.transform(X[y == 0]), float) # sample drawn from class 0
d1 = np.asarray(rep.transform(X[y == 1]), float) # sample drawn from class 1
x = np.arange(2)
fig, ax = plt.subplots(figsize=(5.6, 3))
ax.bar(x - 0.19, d0, width=0.38, color="#4477aa", label="sample from class 0")
ax.bar(x + 0.19, d1, width=0.38, color="#cc6677", label="sample from class 1")
ax.set_xticks(x)
ax.set_xticklabels(["mean dist to class 0", "mean dist to class 1"])
ax.set_ylabel("mean distance")
ax.legend(fontsize=8)
fig.tight_layout()
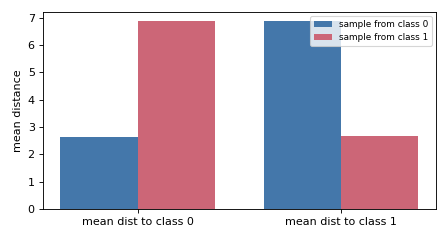
The descriptor is a sample’s mean distance to each class — smallest to its own.#
The metric parameter sets the ground distance (Euclidean, Manhattan, …).
13.1.1.5. Kernel mean representation#
KernelMeanRepresentation embeds a whole sample as a single point — its
mean embedding in a reproducing-kernel Hilbert space (the mean feature vector
under a linear kernel). Each class is summarised by its mean embedding, and MMD
matches the test embedding to a mixture of the class embeddings.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import KernelMeanRepresentation
rng = np.random.default_rng(0)
X0 = rng.normal(-1.3, 0.8, (300, 6))
X1 = rng.normal(1.3, 0.8, (300, 6))
X = np.vstack([X0, X1])
y = np.r_[np.zeros(300), np.ones(300)].astype(int)
rep = KernelMeanRepresentation(kernel="linear").fit(X, y)
e0 = np.asarray(rep.transform(X[y == 0]), float) # class-0 mean embedding
e1 = np.asarray(rep.transform(X[y == 1]), float)
feat = np.arange(len(e0))
fig, ax = plt.subplots(figsize=(6.2, 3))
ax.bar(feat - 0.19, e0, width=0.38, color="#4477aa", label="negative class")
ax.bar(feat + 0.19, e1, width=0.38, color="#cc6677", label="positive class")
ax.set_xticks(feat)
ax.set_xticklabels([f"f{i}" for i in feat])
ax.set_xlabel("feature")
ax.set_ylabel("mean embedding")
ax.legend(fontsize=8)
fig.tight_layout()
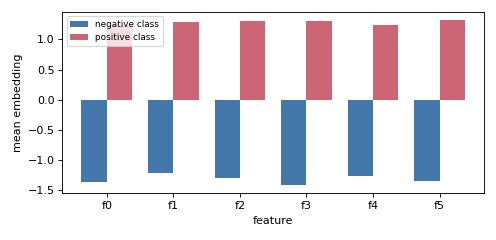
Each class is one mean-embedding vector; MMD matches the test mixture to these.#
The kernel / gamma parameters choose the RKHS (an 'rbf' kernel makes
the matching universal, capturing all moments rather than just the mean).
13.1.1.6. Prediction representation#
PredictionRepresentation summarises classifier outputs as either the
mean posterior (method='soft') or the class-frequency of the argmax labels
(method='hard', i.e. Classify-and-Count). The hard descriptor discards
confidence and is more peaked toward the majority predicted class. These
descriptors feed the constrained-regression counting methods.
import numpy as np
import matplotlib.pyplot as plt
from mlquantify.representations import PredictionRepresentation
rng = np.random.default_rng(5)
proba = rng.dirichlet([3, 2, 2], size=500) # 3-class posteriors
y = proba.argmax(1)
soft = np.asarray(PredictionRepresentation(method="soft").fit(proba, y).transform(proba))
hard = np.asarray(PredictionRepresentation(method="hard").fit(proba, y).transform(proba))
x = np.arange(3)
fig, ax = plt.subplots(figsize=(5.4, 3))
ax.bar(x - 0.19, soft, width=0.38, color="#2a7ab9",
label="method='soft' (mean posterior)")
ax.bar(x + 0.19, hard, width=0.38, color="#b9542a",
label="method='hard' (class frequency = CC)")
ax.set_xticks(x)
ax.set_xticklabels([f"class {i}" for i in x])
ax.set_ylabel("descriptor value")
ax.legend(fontsize=8)
fig.tight_layout()
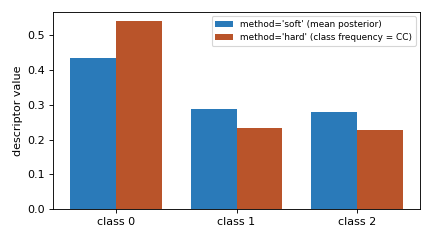
'soft' keeps the posterior mass; 'hard' collapses it to argmax counts.#
HardPredictionRepresentation and SoftPredictionRepresentation
are the fixed-mode variants.
13.1.1.7. Summary and how to choose#
Representation |
What it computes |
Used by |
Tuned by |
|---|---|---|---|
Per-class binned probability-mass vectors of the scores. |
DyS, HDy, HDx, GHDy, GHDx |
|
|
Per-class smooth multivariate densities over posteriors. |
KDEyML, KDEyHD, KDEyCS, GKDEyML |
|
|
Mean distance to each class (energy-distance terms). |
EDy, EDx |
|
|
Mean embedding of a sample in an RKHS. |
MMD_RKHS |
|
|
Mean posterior (soft) or class-frequency (hard) vector. |
GACC, GPACC, FM |
|
Choosing one:
Histogram — cheap and interpretable, but bin-sensitive and degrades on the high-dimensional posterior simplex; prefer it for binary score matching.
KDE — replaces bins with smooth densities and scales to several classes; use it for multiclass density matching.
Distance and kernel mean — bin-free descriptors that summarise a whole sample as a compact vector, used by the energy-distance and MMD methods.
Prediction — the soft/hard descriptors that feed the constrained-regression counting methods.
13.1.1.8. Example#
from mlquantify.representations import HistogramRepresentation
rep = HistogramRepresentation(bins=(10,))
rep.fit(train_scores, y_train)
test_representation = rep.transform(test_scores)
13.1.1.9. References#
References
González-Castro, V., Alaiz-Rodríguez, R., & Alegre, E. (2013). Class Distribution Estimation Based on the Hellinger Distance. Information Sciences, 218, 146–164. (histogram)
Moreo, A., González, P., & del Coz, J. J. (2024). Kernel Density Estimation for Multiclass Quantification. Machine Learning, 113, 3075–3107. (KDE)
Iyer, A., Nath, S., & Sarawagi, S. (2014). Maximum Mean Discrepancy for Class Ratio Estimation. ICML, 32. (kernel mean)
See also
Loss Functions and Solvers for the other two elements of the matching triple.